⇡#Полуторка и Оверсайз
Не так давно, в конце июля, разработчики генеративного искусственного интеллекта (ИИ) для визуализации текстовых подсказок из Stability.ai объявили о выпуске в свободное, что называется, плавание очередной своей базовой модели — Stable Diffusion XL (SDXL) версии 1.0 (предварительные её версии были доступны для широкого тестирования энтузиастами и ранее). Различия между архитектурами SDXL и предыдущих моделей (SD 1.4, SD 1.5, SD 2.1) достаточно глубоки, чтобы заслуживать особого рассмотрения. На практике же важно, что старая добрая «Полуторка», которую не смогла за много месяцев потеснить с пьедестала даже вроде бы куда более прогрессивная SD 2.1, ещё на достаточно долгое время продолжит оставаться предпочтительным вариантом для локального ИИ-рисования.

Именно локального: облачные ресурсы, предлагающие доступ к SDXL (в первую очередь, поддерживаемый самою же Stability.ai сайт clipdrop.co или известный mage.space, на котором SDXL 1.0 стала теперь базовой моделью по умолчанию), наверняка окажутся более популярными у широкого круга интересующихся Иизобразительным Иискусством, чем аналогичные площадки, предоставляющие доступ к чекпойнтам на основе SD 1.5. Причина проста: в базовой комплектации SDXL объективно выдаёт более привлекательные изображения на основе более лаконичных и незамысловатых подсказок, чем «Полуторка».
Привлекательные в довольно широком смысле: это и более качественная проработка мелких элементов (исходное штатное разрешение создаваемого образа у SDXL 1.0 — 1024 × 1024, у SD 1.5 — 512 × 512), и более убедительная освещённость сгенерированных сцен, включая достоверные световые рефлексы на поверхностях различной фактуры, и приближенные к естественным контрастность и яркость фотореалистичных изображений. Кисти рук новая модель по-прежнему генерирует пока далеко не всегда идеально (хотя удаётся ей это объективно чаще, чем «Полуторке», в особенности базовой модели SD 1.5, не прошедшей дополнительную тренировку), а вот с текстами справляется не в пример лучше своих предшественниц. Да и в целом один тот факт, что SD 1.5 тренировалась исходно на массиве примерно в 90 млн аннотированных изображений, а SDXL 1.0 — на выборке в 6,6 млрд (точнее, 3,5 млрд картинок пошли на обучение лишь первичного преобразователя текста в образ низкого разрешения, а весь объём в 6,6 млрд — на блок «чистовой отделки» (refiner), формирующий итоговую картинку 1024х1024), уже говорит о многом.

Тем не менее на Civitai — самом, наверное, популярном ныне в Сети репозитории свободно распространяемых ИИ-моделей для преобразования текста в картинки — у базовой версии SDXL 1.0 на начало августа — 1,5 тыс. «лайков» и 22 тыс. загрузок, тогда как у одного из самых востребованных чекпойнтов на основе SD 1.5, DreamShaper, — 29 тыс. «лайков» и 411 тыс. загрузок. И даже не столько из-за того, что первая страничка активна немногим более недели, тогда как вторая — с января 2023-го. Многие энтузиасты, решаясь скачать SDXL 1.0 для запуска на локальной машине, сталкиваются с целым рядом трудностей, начиная от проблем с интеграцией этой модели в AUTOMATIC1111 и заканчивая отсутствием широкого спектра дополнительных инструментов, таких как текстовые инверсии, LoRA, бережливо использующие видеопамять апскейлеры и т. п.
Понятно, что в основном речь идёт о болезнях роста: уже через месяц-другой сообщество энтузиастов наверняка наработает для нового «Оверсайза» (SDXL) версии 1.0 едва ли не более обширный инструментарий, чем для SD 1.5 за аналогичный период времени с момента выкладки модели в общий доступ. И тем не менее продолжать изучать средства оптимизации выдаваемых ИИ рисунков имеет смысл пока что на основе старой доброй «Полуторки» — и в рамках рабочей среды AUTOMATIC1111, уже хорошо знакомой читателям прежних наших «Мастерских» по этой теме: HOWTO: как установить и настроить собственный ИИ на игровом ПК и Практикум по ИИ-рисованию, часть вторая.
Для SDXL 1.0 же, если вдруг кому-то захочется с ней поэкспериментировать в нынешнем её состоянии, можно порекомендовать рабочую среду ComfiUI: с не самым олдскульным интерфейсом, зато в программном плане отлично оптимизированную именно под «Оверсайз», вплоть до того, что на видеокартах с 6 Гбайт памяти модель работает с вполне приемлемой скоростью.
⇡#Сверим часы
Хотя все описанные в рамках настоящей «Мастерской» этапы генерации картинок и последующего их усовершенствования при помощи ИИ вполне выполнимы и на более ранних версиях AUTOMATIC1111, в общем случае разумно будет проапгрейдиться до наиболее свежей — на начало августа её номер 1.5.1. Кроме того, методологически полезно научиться модернизировать установленные через Git программные пакеты вручную (или в полуавтоматическом режиме через стартовый BAT-файл, как будет продемонстрировано чуть ниже) — это может оказаться полезным не только в приложении к ИИ-рисованию.
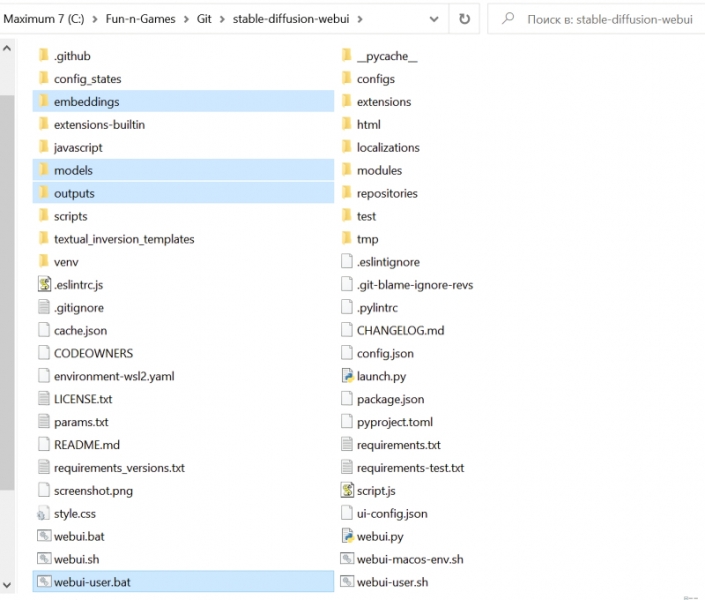
Первое, насчет чего обязан проявить деятельное беспокойство каждый энтузиаст какой бы то ни было деятельности, результатом которой становятся размещённые на локальном ПК файлы, — это о резервном копировании. Процесс обновления версий рабочей среды AUTOMATIC1111 не предусматривает полной перезаписи исходного каталога и тем более удаления ранее сгенерированных и хранящихся внутри него картинок, но перебдеть в данном случае существенно лучше, чем недобдеть. На любой носитель данных, внешний по отношению к логическому диску, на котором развёрнуты клиент Git и эта рабочая среда, скопируйте из главного каталога stable-diffusion-webui папки embeddings (там лежат текстовые инверсии), models (модели бывают разные, но в ходе предыдущих занятий мы закачивали в её подкаталоги в основном LoRA и чекпойнты; дотренированные и оптимизированные в сторону сокращения размера разновидности базовой модели SD 1.5), outputs (вот это попросту бесценно — здесь по умолчанию лежат все наши прежние картинки-генерации!), а также файл webui-user.bat с модифицированными параметрами запуска. На бэкап может потребоваться и несколько десятков Гбайт, всё определяется размером папки с чекпойнтами и, в гораздо меньшей степени, каталога с готовыми картинками.
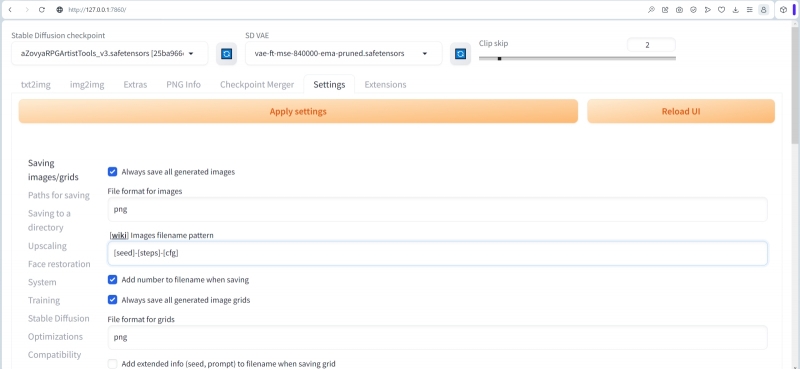
Следующий шаг — позаботиться о настройках веб-интерфейса, которые в ходе апдейта могут ненароком слететь. Более того, пользуясь случаем, ряд этих настроек неплохо бы заодно и оптимизировать. Так, в разделе «Settings» первый же из выстроенных слева столбиком подпунктов, «Saving images/grids», содержит поле для задания «Images filename pattern» — шаблонов именования файлов.
По умолчанию этот шаблон тривиален: картинки помещаются в папку внутри каталога outputs, соответствующую способу их генерации («txt2img-images», например, — это для изображений, полученных непосредственно по текстовым подсказкам), и в подпапку, имя которой определяется текущей датой (скажем, «2023-08-02»). Внутри этой папки нижнего уровня каждая очередная картинка из последовательно попадающих туда получает порядковый номер, за которым через дефис следует значение «seed» — затравки, послужившей основой для процедуры извлечения осмысленного (на человеческий взгляд) изображения из хтонических бездн латентного пространства. В этом, собственно, и заключается суть ИИ-генерации методом устойчивого [обратного] рассеяния — stable diffusion.
Поскольку мы намереваемся в дальнейшем экспериментировать, есть смысл присваивать имена картинкам по более развёрнутой легенде, указывая в наименовании соответствующего файла не только затравку, но и число шагов, и CFG (classifier free guidance, «свободный параметр классификатора» — подробнее о нём см. предыдущий выпуск «Мастерской» по ИИ-рисованию). Так что в поле «Images filename pattern» следует задать следующий шаблон:
[seed]-[steps]-[cfg]
Там же, на страничке, присутствует ссылка на Вики, что базируется прямо на GitHub, — интересующиеся могут в любой момент изучить конвенцию именования более детально. Удостоверимся также, что галочки стоят у позиций «Add number to filename when saving» и «Always save all generated image grids». Последняя пригодится, когда дело дойдёт до создания за один присест не одиночных изображений, а целых их упорядоченных наборов (grids) по заранее указанным правилам. Такие наборы полезно формировать для изучения возможностей чекпойнтов, текстовых инверсий, различных параметров в полях текстовых подсказок — словом, для экспериментаторства.
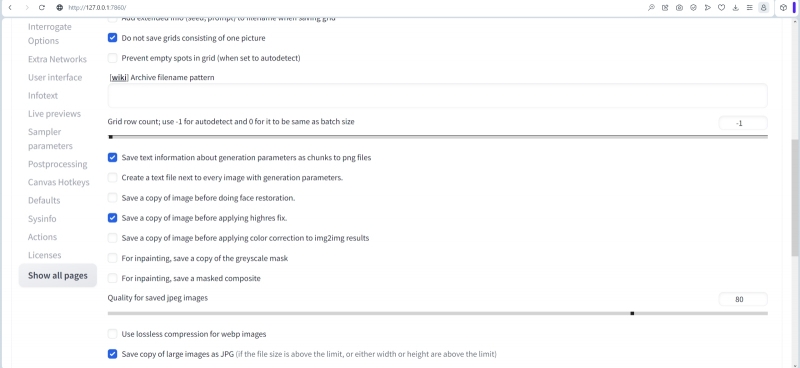
Ниже на той же странице потребуется отметить галочками (или подтвердить для себя, что они уже стоят в нужных позициях) следующие пункты:
- «Save text information about generation parameters as chunks to png files» — это важно для сохранения данных о генерации внутри картинки. Может оказаться полезной и активация пункта «Create a text file next to every image with generation parameters»: в результате в папке с картинками каждое изображение (по умолчанию — файл в формате PNG) будет сопровождать ещё и TXT-файл с тем же названием и явно прописанными параметрами генерации в нём. Да, получить эти параметры и так несложно, перетащив мышкой сгенерированную картинку в соответствующее поле на вкладке «PNG Info», — этот фокус мы уже неоднократно проделывали в предыдущих «Мастерских». Но иногда и отдельный текстовый файлик, уже готовый к быстрому просмотру, может оказаться полезным.
- «Save a copy of image before applying highres fix» — пригодится в случае применения этой самой корректировки с увеличением разрешения (подменю «Highres fix» на вкладке «txt2img»). Ранее мы такой корректировкой не пользовались, предпочитая перемещать сгенерированную в низком разрешении картинку на вкладку «img2img» и работать с ней там явным образом, вручную. Однако авторы некоторых чекпойнтов прямо рекомендуют использовать Highres fix всякий раз при создании нового изображения. В этом случае полезно будет иметь возможность сравнить, какой была изначально сгенерированная картинка и какой она стала после применения автоматизированной корректировки.
- «Save copy of large images as JPG» — эта опция очень поможет при генерации больших упорядоченных наборов изображений, например, с применением встроенного в AUTOMATIC1111 скрипта «X/Y/Z Plot». Сохранённые как PNG, большие сводные таблицы картинок, созданных с разными параметрами, удобны для детального сравнения, но не всякая видеокарта (и не всякое ПО для просмотра изображений!) потянет открытие файла в, допустим, 120-130 Мбайт. Автоматическое создание его копии в JPG, да ещё и с компрессией, значительно облегчает последующее изучение полученного материала.
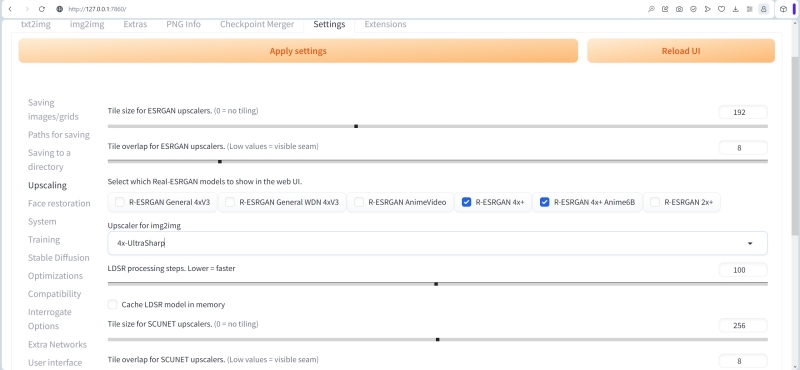
Всё на той же вкладке «Settings», но уже в строке «Upscaling» разумно заняться упорядочением предлагаемого системой разнообразия опций. В частности, для наращивания разрешения картинки с усилением детализации (upscaling) оставим лишь апскейлеры семейства R-ESRGAN 4x+, упомянутые в прошлом выпуске «Мастерской». В качестве апскейлера по умолчанию на вкладке «Img2img» — селектор Upscaler for img2img — выберем 4x-UltraSharp.
В исходный комплект поставки AUTOMATIC1111 он, кстати говоря, не входит. Это не мешает его пользователям оставлять о нём едва ли не более восторженные отзывы, чем обо всех прочих вместе взятых. Как и прочие обсуждаемые в приложении к Stable Diffusion модели — чекпойнты, LoRA, текстовые инверсии и пр., — апскейлер представляет собой скрипт на языке Python, в данном случае файл 4x-UltraSharp.pth, и скачать его можно с соответствующего репозитория на уже знакомом нашим читателям сайте Hugging Face. После скачивания (внимание, это важный момент!) файл следует поместить в каталог ..Gitstable-diffusion-webuimodelsESRGAN (именно туда обращается AUTOMATIC1111 в поисках нестандартных для себя апскейлеров, когда пользователь активирует соответствующую опцию), после чего перезапустить веб-интерфейс — можно просто нажатием клавиши F5.
⇡#Тонкая донастройка
В строке выбора групп параметров настройки «Stable Diffusion», в самом низу страницы, есть переключатель «Random number generator source».
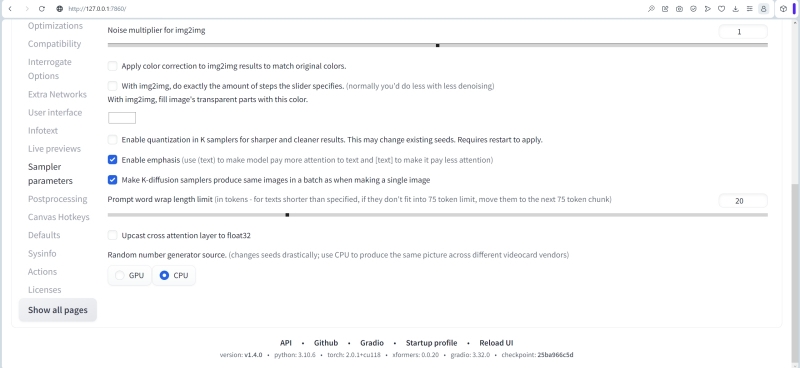
Смысл его в целом очевиден: генераторы случайных чисел имеются и в центральных процессорах, и в графических. Всплывающая подсказка от автора AUTOMATIC1111 недвусмысленно информирует: «Changes seeds drastically; use CPU to produce the same picture across different videocard vendors». Иными словами, получение затравок для дальнейшего создания изображений на ГП разных вендоров реализуется по-разному. Поэтому, если есть желание обеспечить заведомую воспроизводимость однажды полученных результатов — удачно подобранной комбинации текстовых подсказок, seed, числа шагов генерации, CFG, — разумно перевести данный переключатель в положение CPU. И тогда на разных компьютерах (с разными видеокартами) одна и та же затравка будет генерировать в целом одну и ту же начальную картинку, тот пёстрый ковёр из разноцветных пятнышек, который затем преобразуется в изображение в соответствии с входными параметрами системы. А вот если доверить эту генерацию ГП, тут уже возможны варианты.
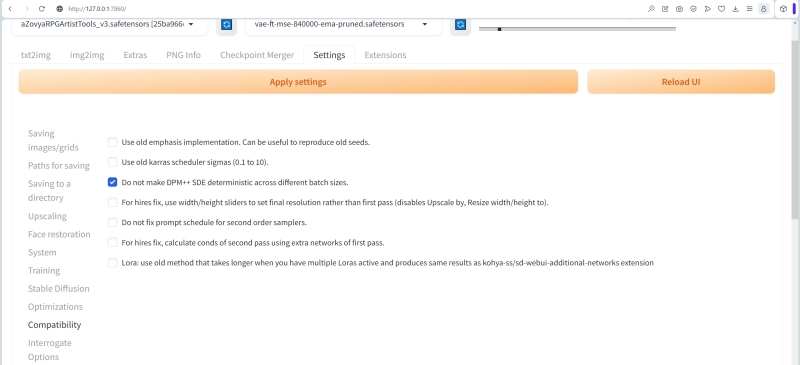
В разделе Compatibility принято ставить галочку в позиции «Do not make DPM++ SDE deterministic across different batch sizes». В данном случае это имеет некоторое значение, поскольку мы ориентируемся в рамках настоящей «Мастерской» именно на DPM++ SDE (в варианте Karras) в качестве основного рабочего сэмплера. Для экспериментирования и освоения AUTOMATIC1111 эта галочка не так уж важна, но её наличие опять-таки становится принципиальным, если у пользователя возникает желание воспроизвести на локальной системе некоторую картинку, параметры которой ему точно известны: скажем, на уже упомянутом репозитории Civitai в галереях предостаточно изображений со строго зафиксированными исходными данными генерации.
История появления этой опции довольно поучительна. Где-то в начале 2023 г. автор AUTOMATIC1111 исправил ошибку, из-за которой картинки с одними и теми же исходными параметрами генерировались сэмплерами DPM++ SDE несколько по-разному в зависимости от того, задавалось ли оператором создание одиночного изображения или же сразу их серии (batch) — с одним и тем же стартовым seed. К середине февраля баг устранили, но тут выяснилось, что многие из созданных прежде картинок не удаётся теперь воспроизводить один к одному. Так и появилась в настройках эта опция совместимости. Начинающим пользователям данной рабочей среды полезно о ней знать хотя бы для того, чтобы не винить себя или систему, если вдруг та отказывается по вроде бы точно скопированным входным параметрам (среди которых есть указание на сэмплер DPM++ SDE либо DPM++ SDE Karras) воспроизводить в точности то, чего от неё ожидают.
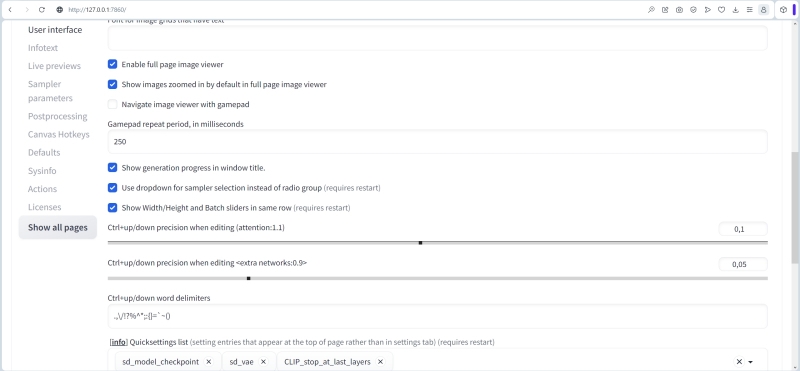
В разделе «User Interface» следует удостовериться, что в перечне «Quicksettings list» указаны, по меньшей мере, эти три опции: «sd_model_checkpoint, sd_vae, CLIP_stop_at_last_layer». Для чего они требуются, мы уже разбирались в прошлых выпусках «Мастерской»; в данном случае важно, чтобы эти настройки успешно пережили грядущий апдейт AUTOMATIC1111.
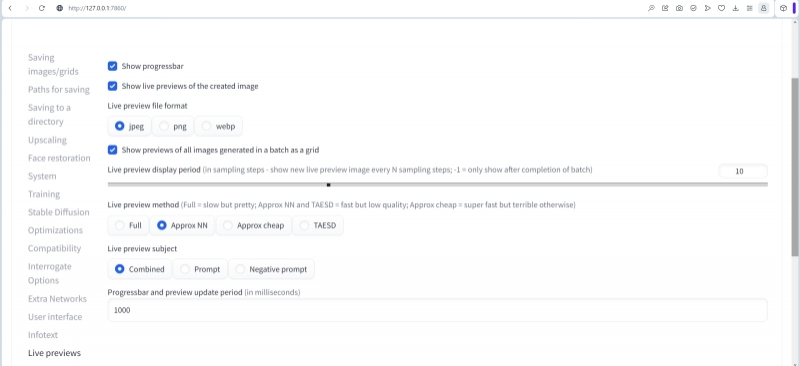
В разделе «LivePreviews» можно настроить, какие именно промежуточные версии итоговой картинки будут демонстрироваться в ходе генерации. Чем медленнее компьютер (в данном случае чем старше и скуднее объёмом памяти его видеокарта), тем дольше перед глазами его пользователя будут висеть эти незавершённые творения ИИ-художника. Так что подход к выбору параметров в данном разделе должен быть скорее эстетическим, нежели практическим.
Хотя и на практике превью бывает очень даже полезно: в том примере с двумя роботами, который мы примемся разбирать ниже, целью первичной генерации будет выбрать картинку, на которой оба андроида изображены в полный рост (в крайнем случае, по колено). Поэтому если уже на нерезком превью заметно, что проступающая из пучин латентного пространства фигура показана по пояс или по грудь, а рисование запущено в бесконечном цикле (по нажатию скрытой кнопки «Generate forever»), логично будет сэкономить машинное время и ресурс видеокарты, нажав на «Skip» и пропустив тем самым доведение текущей генерации до полноценного финала.
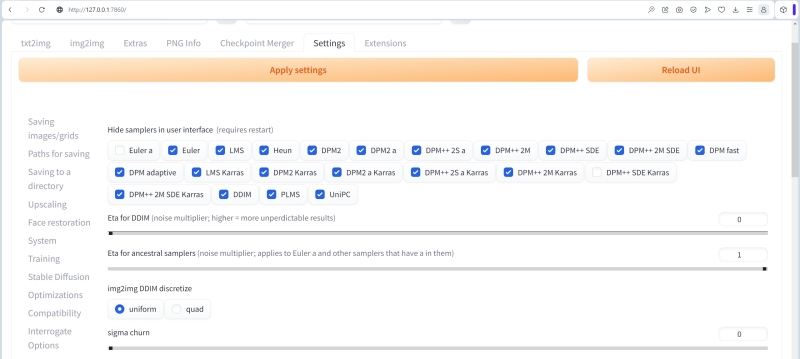
В разделе «Sampler parameters» — и вовсе раздолье для чистейшей вкусовщины. Сэмплеры Euler a и DPM++ SDE Karras необходимо оставить в любом случае: первый, как наиболее популярный, нужен всегда, а вторым мы будем пользоваться постоянно в рамках настоящей «Мастерской». «Предковые» сэмплеры — ancestral; именно оттуда литера «а» в названиях — отличаются повышенной вариативностью при работе с заданной затравкой (seed): изображения с разными количествами шагов генерации и с разными CFG, но с одной и той же затравкой, могут выглядеть порой совсем не похожими одно на другое. Так или иначе, какие сэмплеры оставлять в интерфейсе AUTOMATIC1111 на виду, а какие из них использовать — дело сугубо персональных предпочтений. Наглядно изучить поведение различных сэмплеров в зависимости от разных входных параметров позволит скрипт «X/Y/Z Plot», речь о котором пойдёт в одной из грядущих «Мастерских».
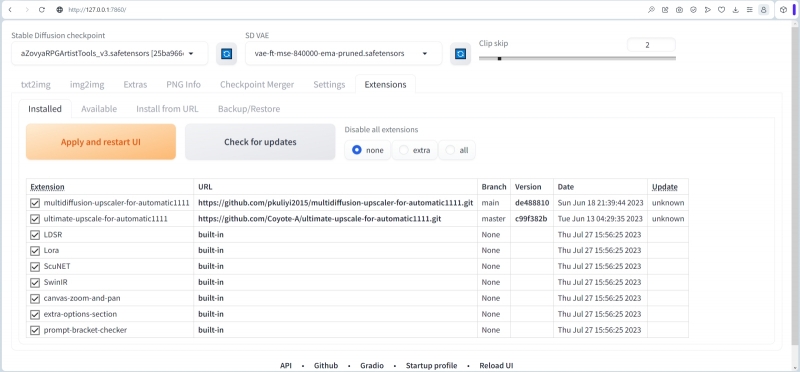
Дальше во вкладке «Extensions» смотрим, какие расширения были нами ранее добавлены в систему. Те, кто на практике воспроизводил приведённые по втором выпуске «Мастерской» по ИИ-рисованию шаги, наверняка увидят у себя в этом разделе как минимум одно установленное расширение — Ultimate SD upscale; оно на данном скриншоте идёт вторым. Что же касается первого Multidiffusion upscaler, то, если его у вас пока нет, ничего страшного: вскоре придёт время заняться им вплотную.
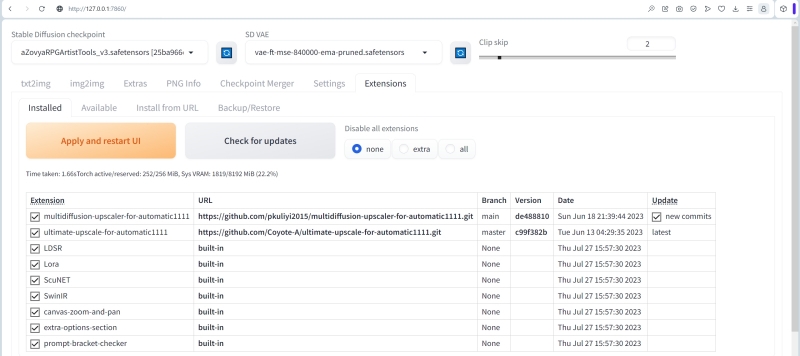
Рабочая среда AUTOMATIC1111, вопреки названию, не всё делает автоматически. Впрочем, с точки зрения немалой доли энтузиастов, имеющих дело со свободно распространяемым ПО, оно и к лучшему: многие предпочитают сами принимать осознанное и информированное решение, что и когда им апдейтить. В частности, на этой же вкладке «Extensions — Installed» предусмотрена ручная проверка наличия обновлений для установленных расширений: нужно щёлкнуть мышкой по большой кнопке «Check for updates». В данном случае выяснилось, что как раз у Multidiffusion upscaler появилось обновление (обозначенное как «new commits»). И его несложно установить, поставив галочку в колонке «Update», а затем нажав на оранжевый транспарант «Apply and restart UI».
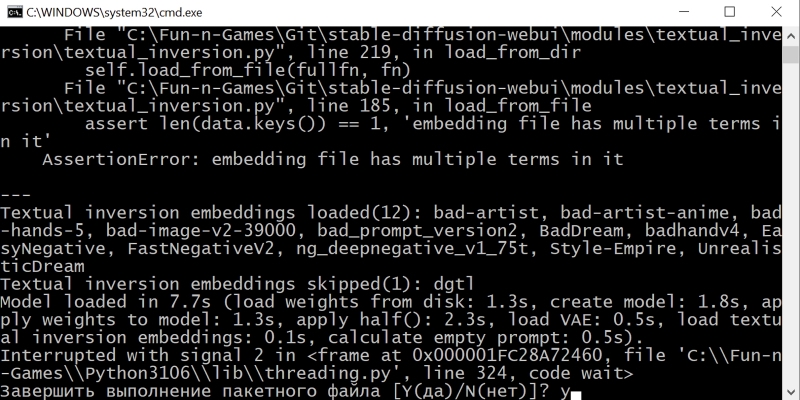
Ну вот, собственно, и всё с проверкой состояния интерфейса. Закрываем в браузере вкладку с AUTOMATIC1111; в окне командной строки, что открылось после запуска файла webui-user.bat, нажимаем Ctrl+C и, после появления подсказки, латинскую «y» без кавычек — а затем Enter.
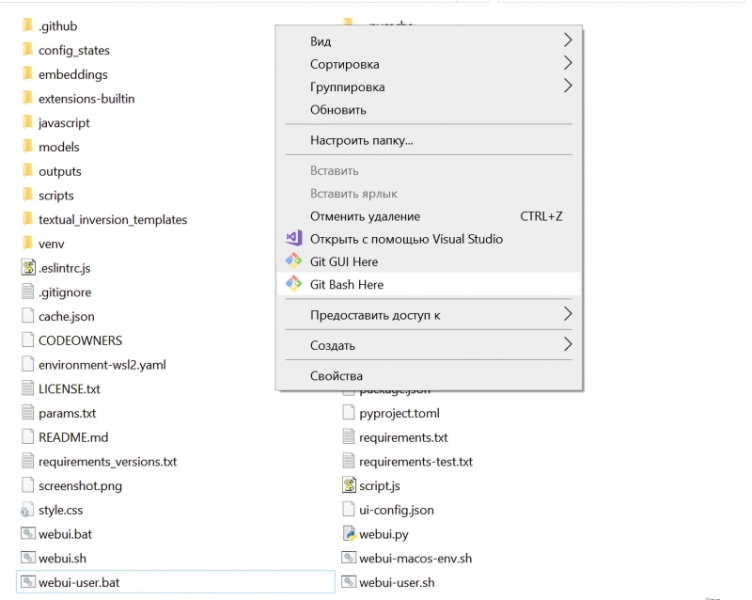
Дальше нужно в окне «Проводника» Windows, в котором открыто содержимое папки ..Gitstable-diffusion-webui, щёлкнуть правой кнопкой мыши и выбрать запуск «Git Bash Here».
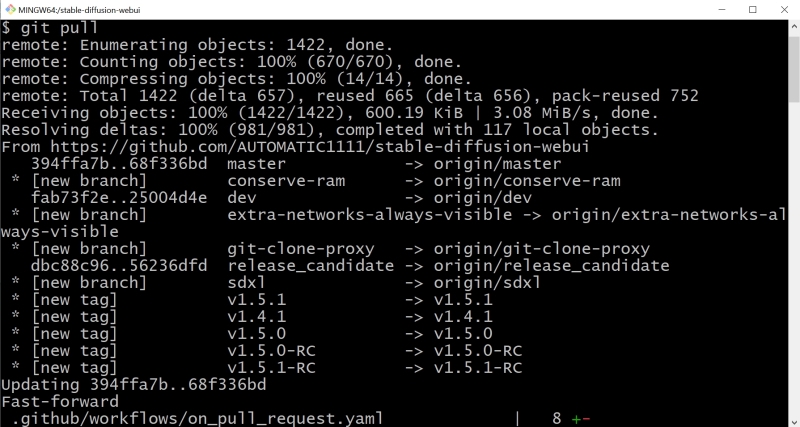
После этого требуется ввести в открывшемся окне команду «git pull» без кавычек, нажать кнопку «Ввод» на клавиатуре и… собственно, всё. Начнётся процесс апдейта скачанного с Git дистрибутива. Занимает это совсем мало времени: самое «тяжёлое» в инструментарии ИИ-рисовальщика — чекпойнты, а рабочая среда AUTOMATIC1111 сама по себе их не содержит.
Некоторые энтузиасты рекомендуют (полу)автоматизировать процедуру регулярного обновления данной рабочей среды, просто добавив «git pull» в её стартовый файл, webui-user.bat, ближе к концу, между строчками «set COMMANDLINE_ARGS» и «call webui.bat». Иногда это в самом деле имеет смысл: скажем, после недавнего апдейта до версии 1.5.0 незамедлительно выяснилось, что AUTOMATIC1111 начал работать с LoRA и иными инструментами не совсем так, как от него ожидали, — и достаточно быстро вслед за этим патчем было выпущено исправление, 1.5.1. И если кто-то вручную скачал версию 1.5.0, а потом погрузился в получение картинок и перестал следить за бурной жизнью сообщества Stable Diffusion (например, в Reddit), у него были все шансы надолго остаться с криво работающими LoRA. С другой стороны, когда пользователи вполне стабильной версии 1.4.0 (из-за настроенного прежде автоапдейта) вдруг ощутили на себе те же самые неприятности, им пришлось либо вручную откатываться на предыдущую версию, либо терпеть несколько дней до публикации исправления. В общем, и плюсы и минусы есть и у ручной, и у автоматической установки обновлений. Главное, что и ту и другую организовать совсем не сложно.
Теперь самое время вновь открыть в браузере http://127.0.0.1:7860 — и удостовериться, прокрутив страничку до конца, что номер актуальной версии AUTOMATIC1111 отображается именно как 1.5.1 (или какой она там будет на тот момент, когда вы произведёте свой апдейт). Самое время переходить от обновления к практике!
⇡#Что же делать?
И вот теперь, после обновления, самое время пояснить, что же это за расширение такое во вкладке «Extensions», multidiffusion-upscaler-for-automatic1111, и откуда оно взялось. Изначально оно носило название Multidiffusion Upscaler, но теперь официально проект называется Tiled Diffusion & VAE, и расположен его код (плюс вводные замечания автора, плюс обсуждения участниками сообщества) тоже, как и в случае с AUTOMATIC1111, на GitHub.
Однако скачивать его оттуда и развёртывать вручную нет необходимости. В той же вкладке «Extensions» рядом с подвкладкой «Installed», на которой мы только что проверяли наличие обновлений у ранее загруженных расширений, есть другая подвкладка — «Available». Перейдя туда и нажав на огромную оранжевую кнопку «Load from», мы точно так же, как и в прошлом выпуске «Мастерской», когда загружали расширение Ultimate SD upscale, получим список доступных к установке расширений из официального репозитория AUTOMATIC1111.
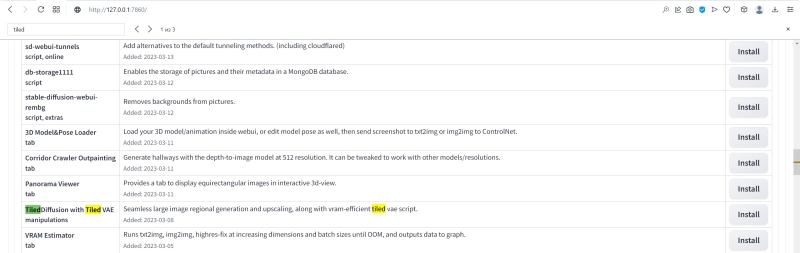
В этом списке и надо по ключевому слову «Tiled» отыскать нужную строку, после чего нажать на серенькую кнопку «Install» справа, а затем, прокрутив ту же самую страницу до самого верха, — «Apply and restart UI».
После перезагрузки в главной рабочей вкладке AUTOMATIC1111, «txt2img», сразу под окном ввода значения затравки появятся два новых выпадающих подменю: «Tiled Diffusion» и «Tiled VAE». С ними теперь и будем работать.
Зачем в принципе нужно дополнительное разбиение картинки на плитки (tiles)? Это один из наиболее действенных способов преодолеть такой врождённый недостаток SD 1.5 и даже 2.1, как откровенно слабые возможности создавать неквадратные изображения. Систему тренировали на десятках миллионов квадратных картинок, и в таком формате она (в базовой своей версии) более или менее готова формировать адекватные образы. Стоит же немного вытянуть холст по одному из направлений, как резко повышается вероятность возникновения артефактов.

При соотношении сторон 4:5 это ещё слабо заметно, но в прямоугольнике от 2:3 и далее получить задвоение указанного в текстовой подсказке объекта уже оказывается проще простого. А происходит это задвоение потому, что обученная на квадратных образцах нейросеть «склонна видеть» в любом прямоугольнике два — по меньшей мере два — частично перекрывающихся квадрата. И хорошо ещё, если прямоугольник горизонтальный: вместо одного, допустим, человека, обозначенного в текстовой подсказке, на картинке с немалой вероятностью появятся два почти близнеца. Если же холст вытянут по вертикали, оригинальная модель SD 1.5 (до того, как в Сети стали появляться первые дотренированные энтузиастами чекпойнты) ничтоже сумняшеся задваивала торсы и/или головы на портретах, довольно органично сопрягая, скажем, талии с шеями… бр-р. Вспоминать не хочется.
Так вот, основное предназначение Tiled Diffusion & VAE — справляться с этой проблемой, разбивая исходный холст на квадраты-тайлы (чаще всего 512х512) и заставляя, по сути, SD 1.5 генерировать изображение квадратными, как она любит, кусками. Но при этом изображение выходит взаимосогласованным — поскольку система получает возможность «заглядывать» в соседние квадраты на заданную глубину. Понятно, что такая многократная разбивка холста, да ещё с наложением «зон внимания» на соседние квадраты, требует значительных ресурсов машинного времени: генерация одиночного изображения с Tiled Diffusion & VAE может занять и вдвое, и втрое больше времени, чем без этого расширения. Зато верхний предел размеров такой картинки, как заверяет автор расширения, составляет почти немыслимые 16384×16384 точки — и это за один проход; без каких бы то ни было дополнительных апскейлов.
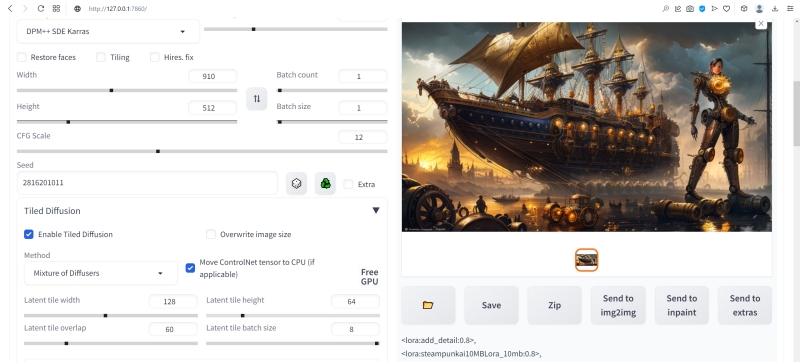
Итак, откроем выпадающее подменю «Tiled Diffusion» и активируем расширение, поставив галочку в поле «Enable Tiled Diffusion». Рядом располагается крайне интересная опция «Overwrite image size». Именно она ответственна за «раздувание» исходной картинки до умопомрачительных размеров без потери композиционной взаимосогласованности (в пределах, заданным возможностями данного чекпойнта и содержанием текстовых подсказок, конечно). Пока не станем её активировать, поскольку на первом этапе мощь Tiled Diffusion & VAE потребуется нам для решения более приземлённой задачи, а именно — для получения заготовки будущих обоев компьютерного «Рабочего стола».
И так как в подавляющем большинстве своем современные мониторы характеризуются соотношением сторон 16:9, взяв для короткой стороны характерный размер базового квадрата модели SD 1.5, т. е. 512 пикселов, для длинной получим 912. Точнее, 910, но в силу определённых особенностей реализации данного расширения длины сторон в его настройках фактически всегда оказываются кратными 4. В этом можно убедиться, если не вписывать вручную «910» в соответствующее окошко, а попытаться получить это число, нажимая на расположенные с его правой стороны крохотные стрелочки вверх и вниз: за «904» сразу же последует «912». Да, прописать «910» вручную возможно, но по факту система округлит это значение до ближайшего подходящего предыдущего, т. е. до 904 — в этом можно будет убедиться, открыв полученную картинку в любом графическом редакторе, который покажет её точные размеры. И поскольку 912 всё же ближе к 910, чем 904, лучше уж остановиться на 912.

Важное замечание: латентное пространство не терпит суеты. Приступая к генерации, ещё на самом раннем этапе настройки рабочей среды следует ясно отдавать себе отчёт: для чего впоследствии будет использоваться полученная удачная картинка? Просто положить в папочку, чтобы потом пересматривать и любоваться? Тогда имеет смысл рисовать в непритязательном квадрате; «Полуторка» именно под это оптимизирована, и дотренированные на её основе модели в общем случае станут выдавать тем более приятные глазу результаты, чем ближе к единице соотношение сторон холста. Нужен портрет некоего персонажа — например, из фэнтезийной настольной игры, которого вы собираетесь отыгрывать? Тут подойдёт соотношение 3:2 в книжном формате. Хочется сгенерировать красивый ландшафт, или вид городской застройки, или антураж некоего помещения — оптимально 2:3, альбомный формат. А уж если требуются именно обои, то тут надо отталкиваться от того, для какого именно устройства они нужны, и брать соответствующее соотношение: 16:9, 10:16, 21:9 и т. п.
Именно Tiled Diffusion & VAE даёт возможность генерировать изображение с необходимым соотношением сторон сразу, за один проход, не тратя времени на многократную дорисовку (outpainting), к которой мы прибегали во второй части настоящей «Мастерской». Безусловно, и в этом случае вряд ли удастся за короткое время наткнуться на совершенно идеальную по композиции и детализации картинку: латентное пространство требует жертв. Наверняка потребуется применять и частичную перерисовку (inpainting), и, вполне возможно, ручную доводку каких-то совсем уж сложных фрагментов (вроде всё тех же кистей рук или — вот парадокс — ручек чайников; SD 1.5 отчего-то с готовностью порождает великолепные изящные чайники с двумя носиками гораздо чаще, чем с носиком и нормальной ручкой) в фоторедакторе.

К тому же, разумеется, на финальном этапе не обойтись без укрупнения с повышением детализации — при помощи скрипта Ultimate SD upscale, как мы это делали в прошлый раз, или же встроенными средствами самого Tiled Diffusion & VAE. Но всё-таки появление изначально удачной существенно неквадратной картинки в отсутствие этого расширения чрезвычайно маловероятно, и потому как раз для обоев его применение более чем оправданно.
⇡#Больше плиток для бога плиток
Зададим те значения ширины (Width) и высоты (Height) холста, о которых только что рассуждали в применении к обоям для мониторов 16:9: 912 и 512 соответственно.
Далее требуется выбрать в выпадающем меню «Method» собственно метод рассеяния всего лишнего с «изначально зашумлённой картинки», в чём и заключается принцип действия Stable Diffusion — «Multidiffusion» или «Mixture of diffusers». Внятных пояснений тому, в чём именно между ними разница, автор расширения не даёт, но практика показывает, что первый метод из этой пары работает быстрее, но и результаты выдаёт несколько менее привлекательные (в широком смысле), чем второй. В любом случае, энтузиастам ИИ-рисования имеет смысл испробовать оба метода — при всех прочих равных параметрах генерации, конечно же, включая затравку, число шагов и CFG, — и решить лично для себя, какой из них в целом лучше. Мы в данном случае возьмём на вооружение «Mixture of diffusers».
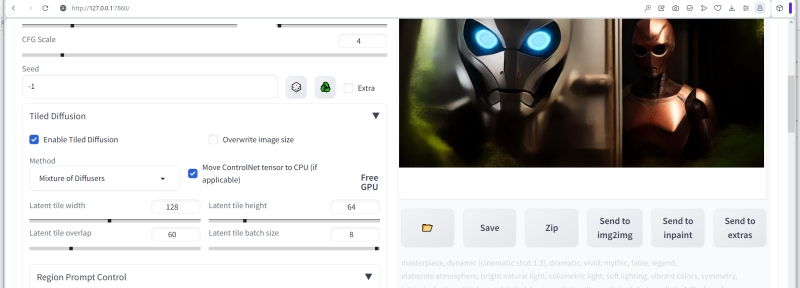
Затем нужно установить размеры единичной плитки (latent tile), на которые будет разбиваться холст для генерации цельного изображения — по одной плитке за раз. Именно благодаря этому инструменту даже на ГП со скудным объёмом видеопамяти данное расширение позволяет создавать обширные цифровые полотна — хоть для обоев «Рабочего стола», хоть для печати в высоком разрешении. Эмпирическое правило, приводимое завзятыми пользователями Tiled Diffusion & VAE, таково: на каждую из сторон холста должно приходиться примерно от 8,5 до 10 плиток — в этом случае самосогласованность итогового изображения заведомо оказывается на высоте. По этой причине в нашем случае логично задать величину «Latent tile width» равной 128, а «Latent tile height» — 64.
Значение «Latent tile overlap» определяет, на какое количество пикселов перекрывают одна другую соседние плитки, обеспечивая сквозную композиционную цельность итогового изображения. В целом, очевидно, что чем больше этот параметр (в разумных пределах, конечно, не выходя за характерный размер одиночной плитки), тем лучше взаимосогласованность на большом масштабе. Но и время на генерацию очевидным образом вырастает кратно по сравнению с тем, что затрачивается на единовременное, безо всяких перекрытий, заполнение цельного холста тех же размеров. Разумным компромиссом представляется здесь брать величину чуть меньше минимального размера плитки — в нашем случае это будет, допустим, 60.
Параметр «Latent tile batch size» задаёт количество одновременно генерируемых системой плиток. Тут всё напрямую зависит от объёма видеопамяти: сколько данных в неё поместится, — но чем больше, тем лучше. На качество изображения это не влияет, зато напрямую определяет время генерации, и потому лучше начинать с максимума — 8, и понижать это значение только в случае появления ошибок из-за переполнения видеопамяти.
Блок «Tiled Diffusion» завершается ещё одним выпадающим подменю, «Region prompt control», — его настоятельно рекомендуется использовать для усиления композиционной связности существенно неквадратных картинок. К настоящему времени для SD 1.5 созданы и более мощные средства управления композиционной связностью, прежде всего ControlNet, с которым мы познакомимся в будущем. Но, во-первых, привязанные к зонам (regions) подсказки — интегрированная в Tiled Diffusion & VAE функциональность; для её реализации не требуется ничего дополнительно инсталлировать. А во-вторых, ControlNet неплохо работает и вместе с зональными подсказками, что значительно усиливает возможности обоих этих инструментов.
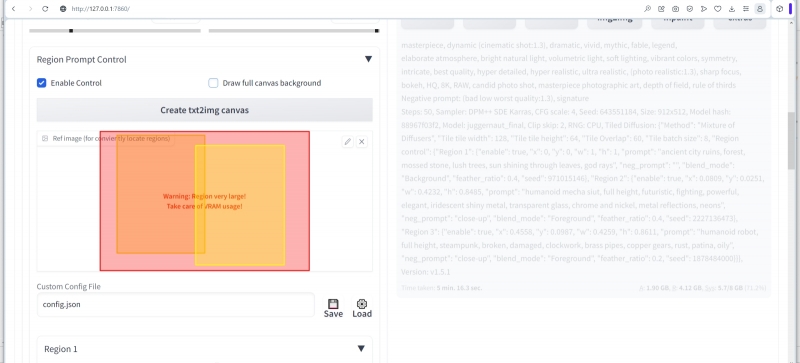
Открыв выпадающее меню «Region prompt control», для начала активируем этот элемент соответствующей галочкой, а заодно отметим и «Draw full canvas background». Эта опция нужна для того, чтобы фон, на котором будут располагаться разбросанные по зонам элементы изображения, стал общим для всей картинки, чтобы она не развалилась на совершенно независимые одна от другой зоны. Ниже располагается длинная серая кнопка «Create txt2img canvas»: после её нажатия появится окошко, в котором можно перемещать, собственно, упомянутые уже не раз зоны — в наглядном представлении цветных полупрозрачных прямоугольников.
Если нажать на небольшую, едва заметную кнопочку с изображением карандаша в правом верхнем углу окошка для рисования, характерный шахматный фон обозначит границы будущей цельной картинки, своего рода макет. Как вариант, можно просто перетащить на это окошко любое готовое изображение с подходящим соотношением сторон — например, если его предполагается использовать в качестве референсного, чтобы располагать объекты генерируемого ИИ рисунка подобно образцу.
Важный момент: намеченные для применения зональных подсказок зоны можно мышкой перетаскивать по этому полю и мышкой же, уцепившись за сторону или за угол, менять их размеры. Но после того, как очередное изменение признано финальным, и сразу перед переходом к началу генерации картинки нужно нажать на «Create txt2img canvas» ещё раз, иначе система может не подхватить корректным образом координаты изменившихся зональных границ.
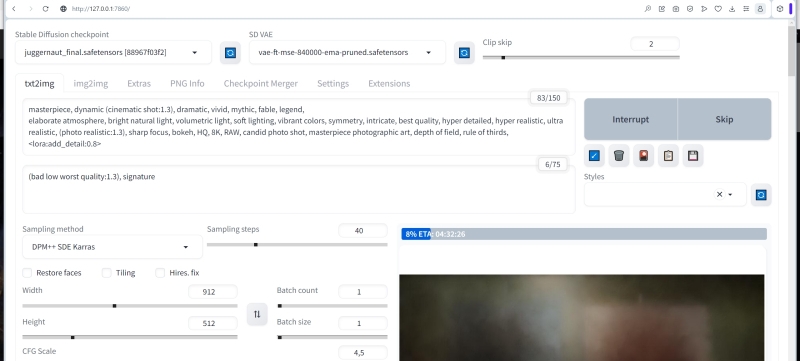
Ну что же, самое время приступать к генерации — точнее, пока что к последовательному вводу всех необходимых для неё параметров. Начнём с самого начала, с выбора собственно генеративных моделей. В качестве рабочего чекпойнта скачаем с Civitai модель Juggernaut в версии Final, достаточно универсальную и, что самое главное, неплохо взаимодействующую с дополнительным инструментарием ИИ-рисовальщика, таким как LoRA и текстовые инверсии. Как водится, помещаем закачанный файл с расширением .safetensor в папку ..Gitstable-diffusion-webuimodelsStable-diffusuion, затем в интерфейсе AUTOMATIC1111 нажимаем на синий квадратик с белыми полукруглыми стрелками у выпадающего меню «Stable Diffusion checkpoint», после чего новозагруженный чекпойнт становится доступным к выбору. Как и в прошлый раз, в меню «SD VAE» выберем vae-ft-mse-840000-ema-pruned, а «Clip skip» установим в значение «2».
Желаемое изображение конкретизируем для себя — это позволит потом вернее составить текстовую подсказку — следующим образом: футуристический робот обнаруживает в неких условных руинах своего давнего предшественника из эпохи стимпанка. Ради пущей динамичности пусть это будут стоящие фигуры; по меньшей мере, в три четверти роста (по колено), а лучше в полный рост. При этом роботы должны быть с первого взгляда хорошо различимы внешне: один — более современный и в движении; другой — архаичный и статичный.

В самом верхнем поле для ввода положительной подсказки соберём тот набор общепринятых в сообществе ИИ-рисования словесных триггеров, что должны отвечать за формирование фотореалистичной, чёткой, высокодетализированной картинки:
masterpiece, dynamic (cinematic shot:1.3), dramatic, vivid, mythic, fable, legend,
elaborate atmosphere, bright natural light, volumetric light, soft lighting, vibrant colors, symmetry, intricate, best quality, hyper detailed, hyper realistic, ultra realistic, (photo realistic:1.3), sharp focus, bokeh, HQ, 8K, RAW, candid photo shot, masterpiece photographic art, depth of field, rule of thirds
Обратите внимание: здесь нет ни слова о роботах или антураже, в котором те должны находиться, — только качественные характеристики изображения в целом (включая такие специальные термины, как «объёмные лучи» или «правило третей»). Негативная подсказка ещё проще:
(bad low worst quality:1.3), signature
Выставляем сэмплер DPM++ SDE Karras, число шагов — 40, значение CFG — 4.5.
Параметры в основном блоке «Tiled Diffusion» у нас уже заданы, займёмся теперь более предметно зональным контролем.
⇡#Обретённые в бездне
Откроем выпадающее меню «Region 1», активируем эту зону («Enable») и зададим следующие параметры: в меню «Type» пусть остаётся «Background» x = 0, y = 0, w = 1, h = 1. Seed оставляем -1, конечно, как и в случае общей подсказки для всего изображения в целом.
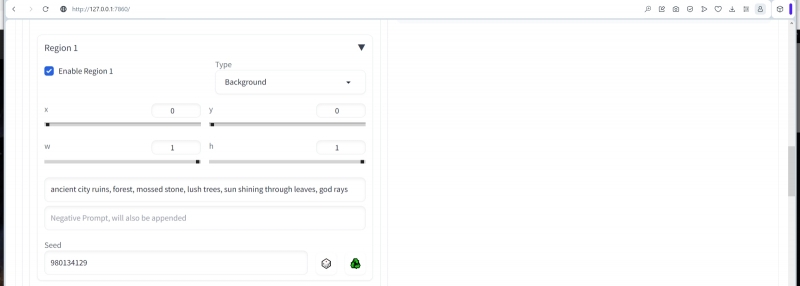
Здесь (x, y) — координаты левого верхнего угла формируемого прямоугольника, а (w, h) — его ширина и длина в долях соответствующих сторон холста в целом. Очевидно, таким образом мы сформировали зону фона, целиком покрывающую всю картинку. В полях, предназначенных для ввода текста, пропишем позитивную зональную подсказку —
ancient city ruins, forest, mossed stone, lush trees, sun shining through leaves, god rays
а поле негативной оставим пустым.
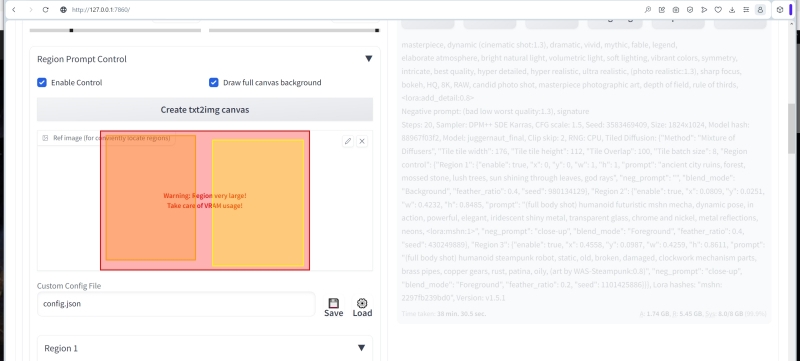
Если теперь прокрутить страничку чуть выше, станет видно, что на графическом представлении зональной структуры будущей нашей картинки появился розоватый прямоугольник, простирающийся на всю площадь холста.
Важный момент: всё, что указывается в текстовых полях каждой из зон, не заменяет общую для всей картинки подсказку, а добавляется к ней. Иными словами, можно было бы перенести описание первой зоны в главную подсказку и вообще обойтись без отдельной зоны для фона, тем более что раньше мы активировали опцию «Draw full canvas background», так что даже таким неявным образом заданный фон рисовался бы общим для всех зон (на основе общей же подсказки).
И тем не менее практика показывает: лучше оставлять в главной подсказке только общее описание того, как должна выглядеть картинка, и переносить в зональные (включая фоновую) всё то, что на ней изображается, эффективно отделяя тем самым латентных мух от таких же котлет.
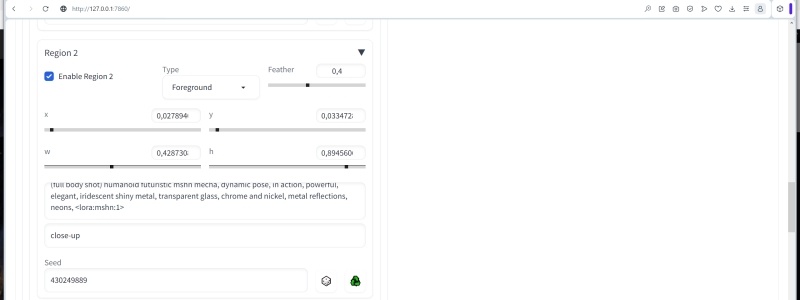
Активируем теперь «Region 2», но делаем его условным «передним планом» (опция «Foreground» в выпадающем меню) с размытием 0,4. Безразмерный коэффициент размытия указывает на то, в какой мере объект должен сливаться с фоном: при нуле он от него полностью и явно, как поясняет в своём комментарии автор Tiled Diffusion & VAE, отграничен; при обращении в единицу — целиком в нём растворяется. Соответственно, объект с размытием 0,4 должен создавать впечатление располагающегося где-то посредине между истинным передним планом готового изображения и его задником. И пусть этим объектом будет как раз футуристический робот (точнее даже, не робот, а «мéха» — механизированный костюм) — с такой позитивной зональной подсказкой:
(full body shot) humanoid futuristic mecha, dynamic pose, in action, powerful, elegant, iridescent shiny metal, transparent glass, chrome and nickel, metal reflections, neons
и краткой негативной, что дополнительно к только что указанному (full body shot) запрещает съёмку с близкой дистанции:
close-up
Границы второй зоны задаём следующим образом:
«x»: 0.0809, «y»: 0.0251, «w»: 0.4232, «h»: 0.8485
Точнее, задаются они, ясное дело, на глаз, перемещением разноцветных прямоугольников в соответствующем окошке чуть выше, а численные значения границ система исправно вписывает в нужные поля и сохраняет затем в свойствах итогового PNG-файла, что даёт возможность с лёгкостью воспроизводить понравившиеся картинки.
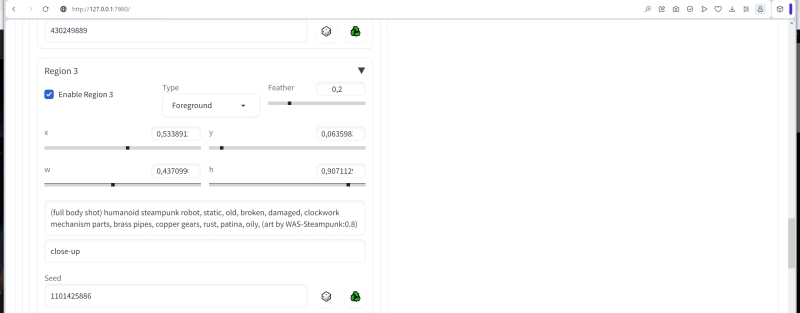
Третья зона — тоже условный «передний план», тоже с размытием, но уже с меньшим, а именно 0,2, чтобы расположить этот объект ближе к зрителю. Объектом же здесь станет стимпанковский робот:
(full body shot) humanoid steampunk robot, static, old, broken, damaged, clockwork mechanism parts, brass pipes, copper gears, rust, patina, oily
с той же негативной подсказкой
close-up
и с границами
«x»: 0.4558, «y»: 0.0987, «w»: 0.4259, «h»: 0.8611
Этого достаточно в плане зональных подсказок, хотя расширение предлагает задавать до восьми зон на генерируемом изображении.
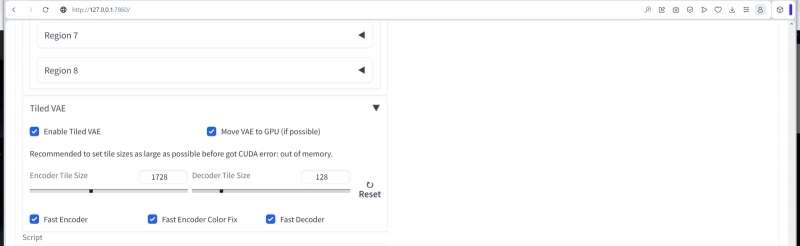
Откроем теперь выпадающее меню «Tiled VAE» и активируем данный элемент. Принцип здесь тот же самый, что и для основного чекпойнта, — разбиение цельной картинки на плитки и генерация их по отдельности. Только уже не для дотренированной основной модели (в нашем случае — juggernaut.final), а для вариационного автокодировщика (variational autoencoder, VAE), дополнительной небольшой нейросети, что действует поверх чекпойнта и улучшает общее качество генерируемой тем картинки в плане цветонасыщенности, чёткости линий, контрастности.
Если объём оперативной памяти позволяет (для 8 Гбайт позволяет точно), VAE следует переместить целиком в видеопамять, чтобы ускорить соответствующие операции, — поставим здесь галочку. Ползунки с числами обычно трогать не надо, пока система сама не даст соответствующей подсказки, а вот если выбрано кодирование с ускорением («Fast Encoder») ради экономии времени, то и «Fast Encoder Color Fix» следует активировать, иначе цветопередача на выходе пострадает.
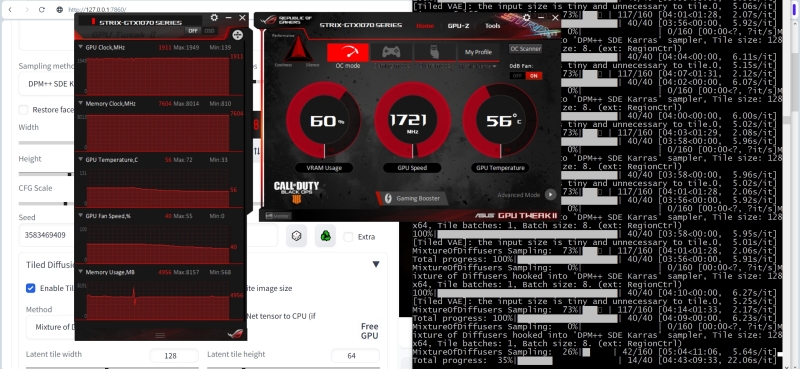
Собственно, всё. Все параметры настроены, зоны размечены, можно приступать к генерации. Прокручиваем страницу до самого верха, жмём на большую оранжевую «Generate» правой кнопкой мыши, выбираем «Generate forever» — и принимаемся за какие-нибудь неотложные (или, наоборот, давно откладывавшиеся и успевшие накопиться) дела. Система же тем временем будет по заданным нами приметам вылавливать из бездны латентного пространства образы и складировать их в соответствующую подпапку каталога ..Gitstable-diffusion-webuioutputstxt2img-images. Загрузка ГП GeForce GTX 1070 не превышает при этом 60%; среднее время генерации одной картинки — чуть больше 4 минут.

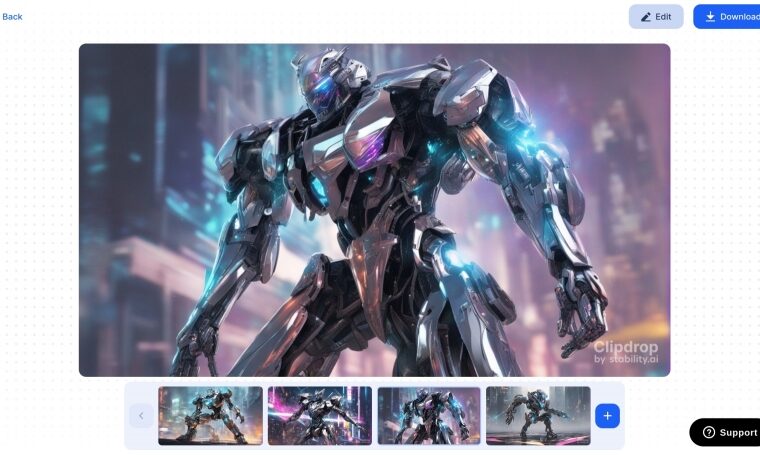
Долго ли, коротко ли, но вот появляется изображение, в котором почти всё хорошо, за исключением футуристического робота. То есть в целом и он ничего, но две тёмные полосы по бокам так неудачно его фланкируют, что частично вырывают объект с заднего плана, особенно правую руку; при этом ноги продолжают уверенно оставаться на логичном как раз для заднего плана месте. Как спасти ситуацию?
Да в целом не так уж и сложно. Берём полученную картинку, переносим во вкладку «PNG Info» — и получаем из текстовой выдачи параметров генерации три затравки: для всего изображения в целом (3583469409), для первой (фоновой) зоны (980134129) и для третьей (стимпанковский робот; 1101425886). Переносим эти числа в соответствующие им поля «Seed» на вкладке «txt2img» (собственно, потому на ряде скриншотов выше эти затравки и можно было видеть), причём из режима «Generate forever» даже нет необходимости выходить: всё спокойно продолжает работать. В результате три затравки при последующих генерациях остаются фиксированными, а одна — для зоны №2 — продолжает всякий раз генерироваться случайно, порождая всё новые и новые варианты футуристических роботов.

Спустя некоторое время две непонятные полосы превратились во фрагменты то ли двери, то ли портала и в целом композиция (с затравкой 430249889 для зоны №2) стала гораздо более приемлемой. Хотя и остальные её части, а не только зона с футуристическим роботом, претерпели некоторые изменения. Не следует забывать, что это всё-таки генерация единого изображения с разбиением на плитки, а поверх них — на зоны: именно поэтому нельзя, жёстко зафиксировав даже три из четырёх рабочих затравок, гарантировать полную неизменность формируемых ими образов. И всё же благодаря зональному контролю объём генераций, необходимых для получения эстетически приемлемой картинки, значительно сокращается по сравнению с тем, который пришлось бы провести с одной-единственной подсказкой, упоминающей разом и древние руины, и двух совершенно разных на вид роботов, да ещё и на столь сильно вытянутом холсте.
⇡#Нет предела совершенству
Нейросеть, обученную на основе текстовых подсказок создавать изображения, при всём желании невозможно научить всему и сразу. Не хватит ни подготовленных материалов (детально аннотированных изображений), ни соответствующих вычислительных мощностей и времени, ни человеческого ресурса. Однако дообучать модель последовательно, раз за разом добавляя в неё новое «знание» (точнее, «интуицию», поскольку машинное обучение подразумевает формирование ассоциативных связей, а не глубокое и осознанное структурирование информации), тоже не вариант: она будет становиться всё более громоздкой, и, вполне вероятно, в процессе формирования новых связей какие-то из прежних будут ослабевать (за этим придётся следить особо).
В начале 2023 г. был найден способ быстрой и довольно простой дотренировки генеративных моделей для преобразования текста в картинки, причём на достаточно узком наборе исходных аннотированных изображений, вплоть до десятков и даже единиц, — LoRA (от Low-rank Adaptation: имеется в виду, что для порождения дополнительных ассоциативных связей здесь требуется меньше параметров и итераций, чем в ходе стандартного первичного натаскивания генеративной модели). Дообученная таким образом система получает возможность применять освоенную ею стилистику (манеру рисунка, цветовую палитру, даже определённый уровень детализации изображений) и/или концепции неких объектов (определённого животного, персонажа, предмета) к любым другим генерациям, словно бы пропуская выдачу базового чекпойнта через дополнительный фильтр.

В числе безусловных достоинств LoRA (по сравнению с DreamBooth, например, более ранним воплощением той же идеи, но несколько иными алгоритмическими средствами) — высокая скорость формирования ассоциативных связей, буквально единицы минут на хорошей современной видеокарте, скромный размер выходного файла модели (десятки, редко сотни Мбайт) и минимальное пенальти по времени генерации одиночной картинки по сравнению с базовой моделью без дополнительных мини-нейросетей. Есть, увы, и недостаток: LoRA не слишком уверенно справляется с человеческими лицами. Воспроизводить почти один в один персонажа аниме или компьютерной игры эта технология позволяет, но для реальных людей некоторая «пластиковость» бросается в глаза, особенно в изображениях, притворяющихся реалистичными фотоснимками. Рисунок «под фотореализм» — дело другое; здесь прибегать к LoRA более чем уместно.
Однако поскольку в нашем случае человеческие лица в принципе не появляются в генерации, применение LoRA более чем оправданно. Чтобы визуально ещё более выделить футуристического робота с полученного нами изображения, применим к нему (точнее, добавим в позитивную подсказку той зоны №2, в которой он генерируется) LoRA, специально обученную на изображениях фантастических промышленных агрегатов, которая так и называется — Industrial Machines. Для этого, напомним, следует скачать со странички проекта на сайте Civitai файл этой мини-модели (большая зелёная кнопка в правом верхнем углу), в данном случае называться он будет mshn.safetensors, и поместить его в папку ..Gitstable-diffusion-webuimodelsLora. После этого в позитивную часть подсказки для зоны №2 дописать специальную команду вызова именно этой LoRA — <lora:mshn:1>. Теперь подсказка эта должна выглядеть так:
(full body shot) humanoid futuristic mshn mecha, dynamic pose, in action, powerful, elegant, iridescent shiny metal, transparent glass, chrome and nickel, metal reflections, neons, <lora:mshn:1>
Негативная же — без изменений:
close-up
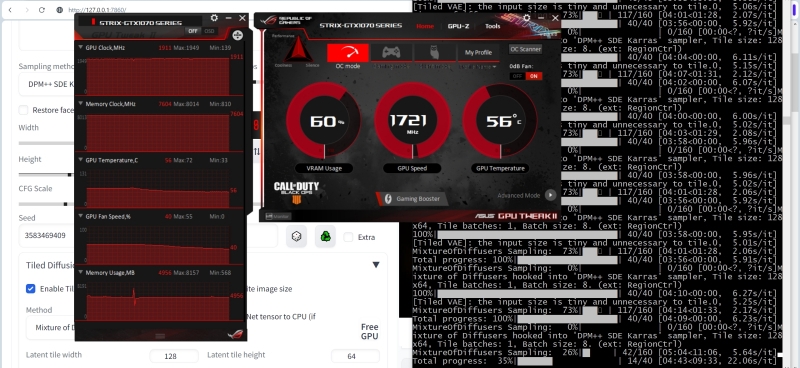
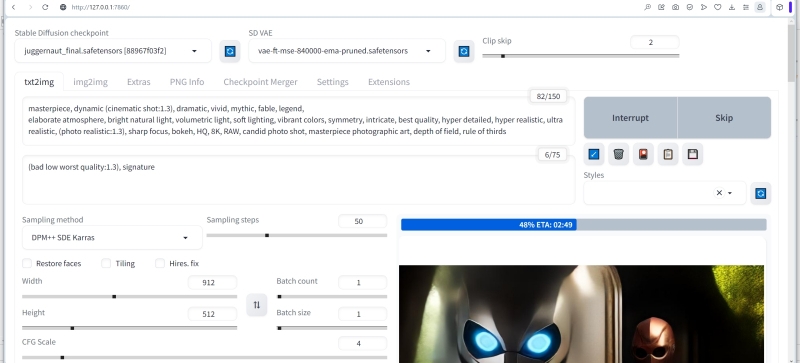
Первое впечатление от применения LoR, ещё до получения собственно картинки: время единичной генерации картинки заметно выросло — с примерно 4 минут до едва ли не 20 (см. оценку системой прошедшего и оставшегося времени на приведённом скриншоте справа внизу)! Вот почему, кстати говоря, всякие украшательства такого рода следует оставлять на потом; откладывать до момента, когда уже определён в целом устраивающий оператора набор затравок (либо единственная затравка, если картинка генерируется без разбиения на зоны). Зато загрузка ГП остаётся на прежнем уровне — в районе 60%.

Картинка явно в целом улучшилась, не только в зоне появления футуристического робота! Опять-таки, как и в ситуации с одной переменной затравкой из четырёх, активация LoRA лишь в одной из зон неизбежно затрагивает остальные.
Никакой мистики тут нет: сама концепция Tiled Diffusion & VAE подразумевает обмен информацией между соседними плитками через частичное их взаимное перекрытие, так что, по сути, чтобы органично вписать в общую композицию любое более или менее серьёзное изменение в одной из зон (границы которой, кстати, расположены произвольно относительно границ плиток), системе оказывается необходимым что-то изменить не только в составляющих её полностью или частично плитках, но и в соседних, и, чуть слабее, в соседних с соседними, и т. д.
Заметим, что часто применение LoRA обычно активируется тем или иным ключевым словом; в данном случае это «mshn». Однако в данном случае, как замечает на страничке Industrial Machines автор проекта, это даже не обязательно.
Скачаем теперь с портала Hugging Face другую LoRA под говорящим названием Add detail, поместим файл её модели в тот же каталог, что и mshn.safetensors, и пропишем её вызов — <lora:add_detail:0.8> — уже в главную подсказку нашего проекта, туда, где описывается общая стилистика получаемого изображения. Выглядит главная подсказка теперь следующим образом: позитивная часть —
masterpiece, dynamic (cinematic shot:1.3), dramatic, vivid, mythic, fable, legend,
elaborate atmosphere, bright natural light, volumetric light, soft lighting, vibrant colors, symmetry, intricate, best quality, hyper detailed, hyper realistic, ultra realistic, (photo realistic:1.3), sharp focus, bokeh, HQ, 8K, RAW, candid photo shot, masterpiece photographic art, depth of field, rule of thirds, <lora:add_detail:0.8>
и негативная —
(bad low worst quality:1.3), signature

И в самом деле, деталей стало значительно больше; футуристический робот по-прежнему динамичен, хотя и несколько поменял позу. Варьируя силу действия каждой LoRA (тот самый параметр после второго двоеточия, который в первом случае у нас равен 1, а во втором — 0,8), можно экспериментировать и дальше, пытаясь добиться наиболее приемлемого, с художественной (во многом субъективной, кстати!) точки зрения, результата. Но сейчас продолжим эксперименты: скачаем с Civitai текстовую инверсию WAS Steampunk (файл was-steampunk.pt) и поместим её в ..Gitstable-diffusion-webuiembeddings. Активируем её (с силой 0,8) для зоны №3, той, где отрисовывается стимпанковский робот:
(full body shot) humanoid steampunk robot, static, old, broken, damaged, clockwork mechanism parts, brass pipes, copper gears, rust, patina, oily, (art by WAS-Steampunk:0.8)
— это позитивная подсказка теперь, а негативная прежняя:
close-up

А вот это прямо совсем хорошо! Да, футуристический робот стал несколько тяжеловеснее из-за контаминации стимпанковской текстовой инверсией, но в целом на этой картинке есть и динамика, и настроение, и вполне ощутимое различие между старой и новой технологиями.

Кстати, специально для интересующихся: вот что получится, если вызов текстовой инверсии (art by WAS-Steampunk:0.8) всего лишь переместить из зональной подсказки в главную, ничего больше в настройках не трогая: прямо-таки «Шерлок Холмс: нерассказанные истории»; викторианский робопатруль на узких улочках Лондона, — даже туман присутствует благодаря фразе «volumetric light» в описании общей стилистики! Теперь, хочется верить, важность корректного позиционирования дополнительных инструментов для преобразования текста в картинки, а именно текстовых инверсий и LoRA, стала очевидной.
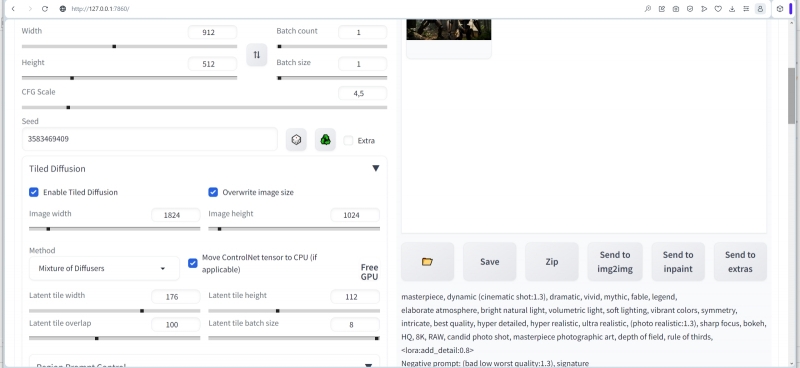
Следующим шагом нашей почти уже завершённой на сегодня «Мастерской» станет использование возможностей Tiled Diffusion & VAE для укрупнения изображений с одновременным повышением детализации, без использования скрипта «Ultimate SD upscale», который помогал нам справиться с этой задачей в прошлый раз. На вкладке «txt2img» вернёмся к разделу «Tiled Diffusion» и поставим галочку в поле «Overwrite image size». Сразу же появятся два ползунка — выставим их в положения 1824 для ширины и 1024 для высоты изображения. Соответствующим образом изменим величины «Latent tile width» — на 176, «Latent tile height» — на 112, «Latent tile overlap» — на 100. В разделе «Tiled VAE» по-прежнему ничего трогать не будем. И — снова нажимаем на «Generate». Процесс занимает чуть больше часа на машине с GeForce GTX 1070.

Вот это поворот! Вот чего ради, собственно, стоило возиться с Tiled Diffusion & VAE. Безусловно, при увеличении картинки взаимоналожение плиток пошло по-иному, чем при генерации исходного малого варианта ровно с теми же затравками и прочим набором параметров, так что итоговое изображение не является просто увеличенной копией первичного. Но и динамики, и напряжения, да и истории в нём, пожалуй, даже больше: достаточно взглянуть на отсутствующую левую стопу футуристического робота, на какое-то явно магазинное оружие в его правой руке и на странно грозное сияние возле предплечья стимпанковского андроида. Картинка вышла настолько впечатляющей, что даже очередной «логотип франшизы» в левом нижнем углу удалять через inpaint нет насущной необходимости: смотрится вполне органично, словно это оригинальная иллюстрация в поддержку некой игры.
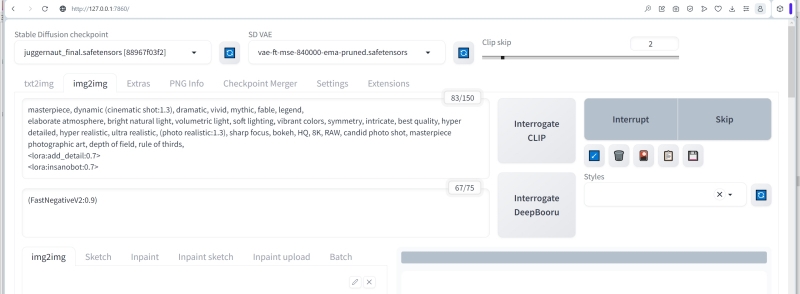
Следует ли на этом останавливаться? Да ни в коем случае! Отправляем полученную картинку с разрешением 1824х1024 на вкладку «img2img» соответствующей кнопкой, что находится справа под окошком предпросмотра генерируемых изображений. Задаём такую общепозитивную подсказку:
masterpiece, dynamic (cinematic shot:1.3), dramatic, vivid, mythic, fable, legend,
elaborate atmosphere, bright natural light, volumetric light, soft lighting, vibrant colors, symmetry, intricate, best quality, hyper detailed, hyper realistic, ultra realistic, (photo realistic:1.3), sharp focus, bokeh, HQ, 8K, RAW, candid photo shot, masterpiece photographic art, depth of field, rule of thirds,
<lora:add_detail:0.7>
<lora:insanobot:0.7>
Последняя LoRA — Insanobot с Civitai: специально создана для генерации как можно более высоко детализированных роботов, киборгов и прочих человекоподобных конструкций. Она срабатывает и в отсутствие слов-триггеров.
Негативная подсказка будет с применением текстовой инверсии Fast Negative Embedding v2, автор которой задался целью собрать воедино все наиболее часто используемые в этой категории понятия, чтобы облегчить жизнь себе и другим ИИ-энтузиастам. Выглядит вся подсказка так:
(FastNegativeV2:0.9)
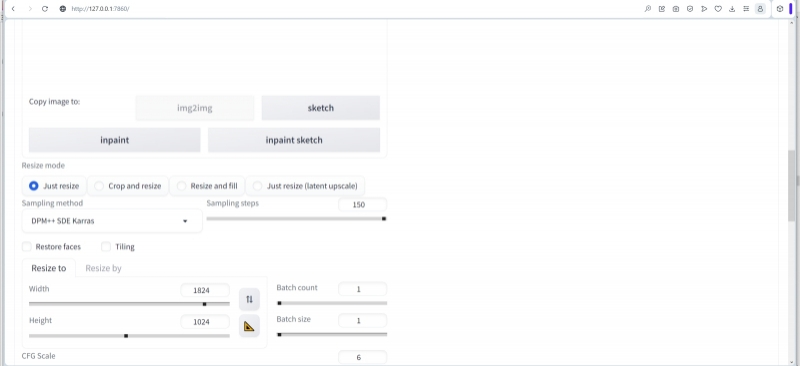
Теперь зададим метод сэмплинга — привычный уже DPM++ SDE Karras, число шагов (Sampling steps) – 150, CFG Scale — 6 (при апскейле креативные порывы ИИ лучше держать под более надёжным контролем, чем в ходе первичной генерации; отсюда — увеличение CFG), Denoising strength — 0,45 (что близко к разумному балансу: намного ниже — дополнительных деталей при апскейле почти не будет появляться; заметно больше — их станет так много, что нарушится исходная композиция), затравка (Seed) — случайная, значение «-1».
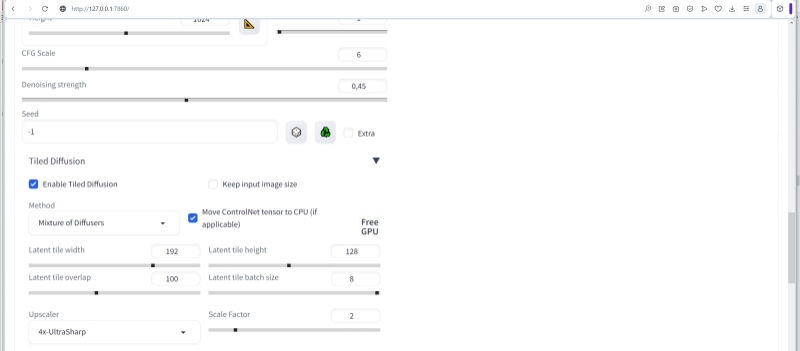
Важно: в данном случае не надо использовать встроенный в AUTOMATIC1111 механизм увеличения разрешения: прибегнем снова к мощи Tiled Diffusion & VAE! Снимаем галочку с опции «Keep input image size», выставляем «Scale Factor» в значение 2. Действующим апскейлером пусть будет 4х UltraSharp, загрузку и установку которого мы упоминали ближе к началу. И, разумеется, здесь не обойтись без активного «Tiled VAE» — конечно, с «Encoder Tile Size» в позиции «1216», например.

Прошло каких-то пять с половиной часов при почти 100%-ной загрузке ГП — и вот он, результат. По техническим причинам в настоящей публикации изображение уменьшено; в оригинальном же размере оно доступно вот здесь. Картинка по настроению и мелким деталям (одно лицо стимпанковского автоматона чего стоит) несколько отличается от исходной, но разве она стала хуже? А если хочется приблизиться к оригиналу, параметр «Denoising strength» следует уменьшить хотя бы до 0,3.
Но есть и другой способ повысить разрешение картинки 1824х1024 вдвое — тот самый, что мы разбирали в прошлый раз, с применением скрипта «Ultimate SD upscale» и точно тех же самых параметров (подсказок, CFG, числа шагов и проч.), как и для Tiled Diffusion & VAE только что.

Здесь система считает быстрее (меньше часа, но тоже при максимальной загрузке ГП), и настроение плюс мелкая детализация снова чуточку иные, более грязноватые, что ли, но вместе с тем более натуралистичные — но опять же, разве картинка стала хуже? В оригинальном размере она доступна по этой ссылке.
Погоня за идеалом в латентном пространстве заранее обречена на провал: всякий раз, когда оператору кажется, будто найден какой-то оптимум — самая правильная текстовая подсказка, самая подходящая LoRA, самые удачные параметры генерации, — вдруг выясняется, что минимальное изменение буквально в одном-единственном месте порождает новый образ и весьма велики шансы, что он окажется ещё привлекательнее первого.
Вот почему полагаться на онлайновые ресурсы настоящие энтузиасты ИИ-рисования не любят: для бесплатной генерации там обычно присутствуют крайне жёсткие ограничения, а платная неизбежно вылетает в копеечку, стоит только начать всерьёз играть с доступными параметрами. А ведь мы за прошедшие три занятия в «Мастерской» пока только лишь приоткрыли дверь в этот невероятный мир, что рождается из пены бурлящего возможностями латентного пространства. То ли ещё будет — оставайтесь с нами!
- Полуторка и Оверсайз
- Сверим часы
- Тонкая донастройка
- Что же делать?
- Больше плиток для бога плиток
- Обретённые в бездне
- Нет предела совершенству